
Image and video restoration and enhancement aim to transform low-quality visuals, such as those suffering from low resolution, noise, compression artifacts, blurring, and various other distortions, into high-quality images and videos. These technologies are critical across numerous applications including computational photography on smartphones, restoration of historical photographs, cultural heritage preservation, artistic creation, digital archiving, medical imaging, and autonomous driving. For videos, these methods significantly enhance film production, video content generation, streaming quality improvement, and more.
Our primary research interests focus on low-level visual processing, alongside related generative and optimization techniques, with particular emphasis on applications in super-resolution. Low-level visual technologies enhance image quality and aesthetics, enabling human observers to better interpret and appreciate visual content and providing improved input for subsequent tasks like object detection, recognition, and tracking. However, with the advancement and widespread adoption of deep learning technologies, low-level visual methods now face numerous challenges and heightened expectations, including demands for higher image quality, improved image assessment methods, and enhanced interpretability of deep visual models.

In 2024, we achieved another major breakthrough with the launch of SUPIR, the first truly large-scale, general-purpose image processing model. SUPIR features over 4 billion parameters and was trained on more than 50 million ultra-high-quality images, surpassing previous datasets by over a thousand times. Capable of handling virtually all common image tasks within a single unified model, SUPIR also supports multimodal image manipulation through text prompts. SUPIR has gained extensive international attention, accumulating over 5.2k stars on GitHub. It has become a standard image upsampling tool within Artificial Intelligence Generated Content (AIGC) workflows, widely utilized across internet platforms and smartphone computational photography products. Training SUPIR required substantial computational resources, including 100,000 GPU hours on a 128-GPU cluster and a research budget exceeding $1 million USD. More details about SUPIR can be explored here.

Building upon SUPIR’s success, in 2025 we introduced HYPIR, a revolutionary advancement in image restoration technology. HYPIR achieves significant performance improvements along with considerably faster training and inference speeds. It excels across various applications including old photo restoration, ultra-high-resolution image generation, and precise text restoration. Additionally, HYPIR has advanced capabilities for accurately interpreting user instructions, allowing flexible adjustments in image restoration detail and style to satisfy personalized needs. Since its release, HYPIR has attracted widespread media coverage, including prominent outlets like China Central Television (CCTV), and rapidly achieved practical implementation in various industries. You can view our detailed introduction video here.
Beyond these core advancements, we continue to actively expand our research into video restoration algorithms, applying our advanced techniques to tackle unique challenges such as temporal consistency, dynamic content handling, and computational efficiency. Our innovative methods have consistently addressed the critical issue of generalization in low-level vision tasks, setting benchmarks in the community and driving advancements in both academic and commercial applications.
Our algorithms continue to have widespread application, integrated into commercial image processing software, diverse products, and numerous smartphone models, thus positively impacting millions of users globally.
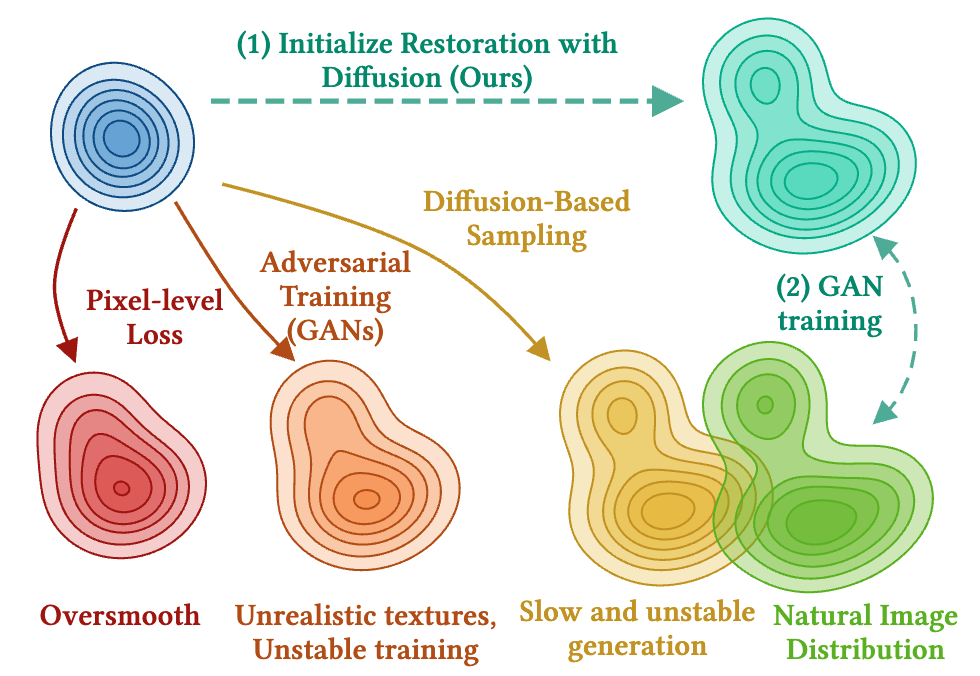 SIGGRAPH Asia
SIGGRAPH Asia
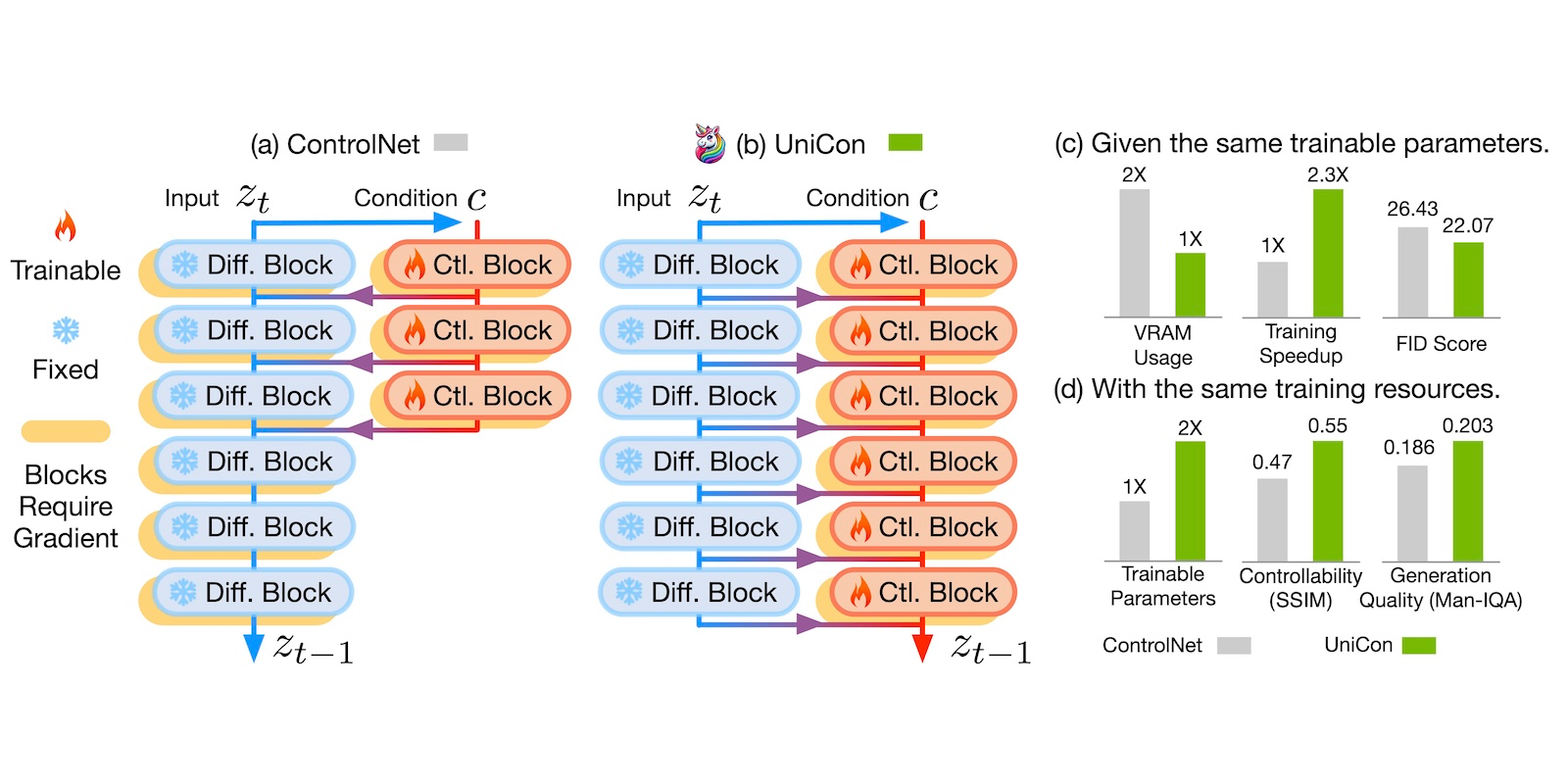 ICLR
ICLR
 CVPR
CVPR
 CVPR
CVPR
 ECCVW
ECCVW
© Copyright 2025 Jinjin Gu.
Last updated: May 10th, 2025.
